Dify x 研究を実現したいと思うと、やはり、論文読解の精度が一番重要なポイントとなります。
RAGを効率的に使用するためにKnowledge構築がとても重要という記事になります。
論文のPDFを渡した際に、LLMは一気にテキストを読んで解釈することはできません。そのため、細かく区切ってセグメント化(細分化、分節化)することで、ユーザーの質問に対して適切なセグメントを抽出するという手法を取っています。
そのため重要なポイントとして
『如何に質問に対して適切なセグメントを取ってくることが可能か』ということになります。
これを満たすためにセグメント化するのに重要なことは
1,セグメントがほどほどの長さではあるが、情報がなくならないこと
2,変な文字等がないことで曖昧な情報とならないように除去すること
ということになります。

多くの場合、上の『Automatic』で行っている場合が多いのではないでしょうか?そうすると、どのような影響があるのか分からないため、下の『Custom』で今回はいろいろな条件を振ってみました。
正直よくわかりません!
とりあえず、解説としては『セグメント化したテキストをコサイン類似度などの指標を用いて類似度を測定し、多次元空間上の一点としてみなし、そのベクトルを数値として表す』
なんのこっちゃ!!
正確には意味はわかりませんが、『細かく区切ったテキストを似通ったもの同士で並べて置いているだな』という印象
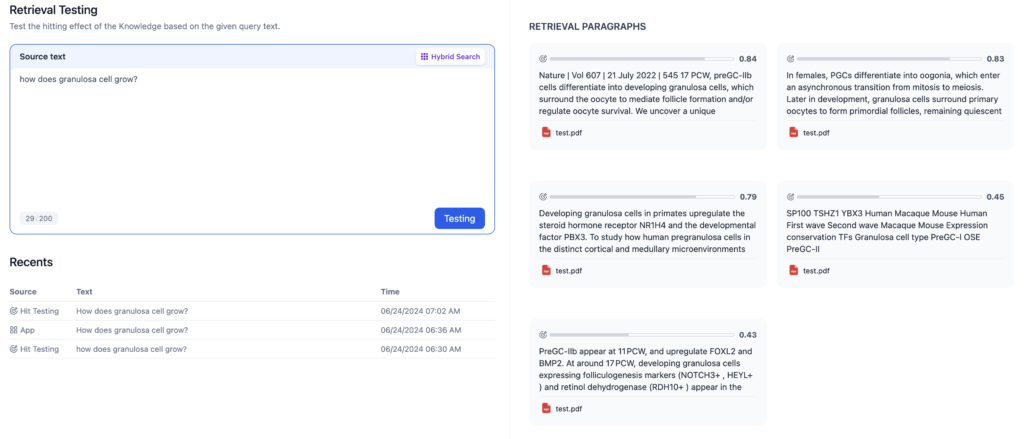
今まで使ってなかったのですが、Knowledgeの中のtestを行うと、LLMに渡す前のセグメント化したテキスト(チャンク)が確認できます。
検索方法は、hybridでTopK=5, Score threshold設定なしで行います。この場合、必ずre-rankされます。(後日検索方法についても解説)
ちなみにテストは下記のKnowledge→赤矢印で実行できます
Segment identifier;\n(改行)
Maximum chunk length;500
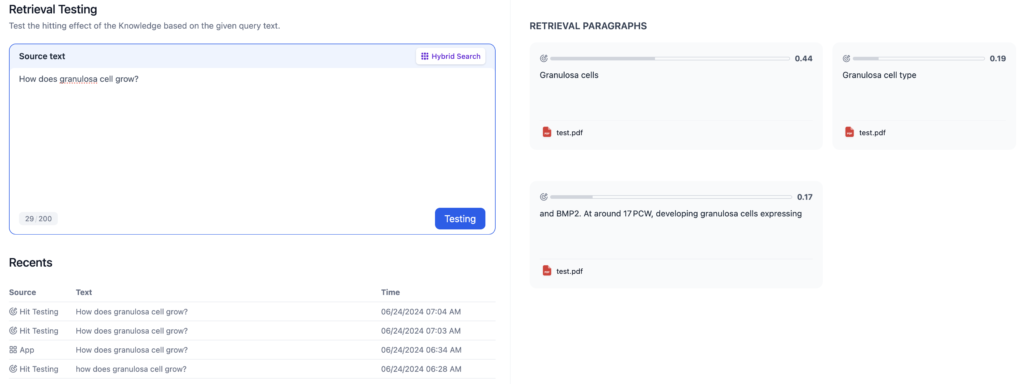
このようにチャンク自体に全然情報が入っていない、、
そのため、ちゃんと元データが読み込まれた時の形式を見ていないと分からない、、
ですが、なんとなく、”#”で分かれているところで区別したらいいのではないか、と考え
Segment identifier;#
Maximum chunk length;100
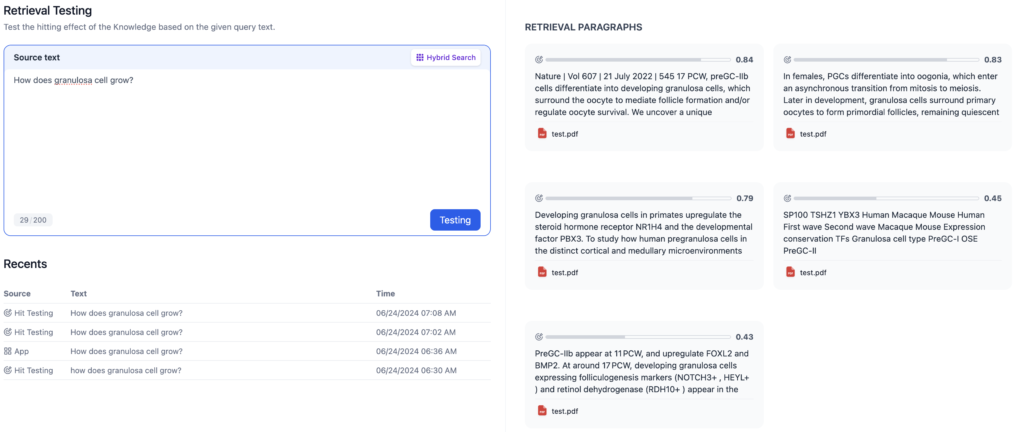
とすると、なんとなく、Automaticっぽい感じになった。
Segment identifier;#
Maximum chunk length;500
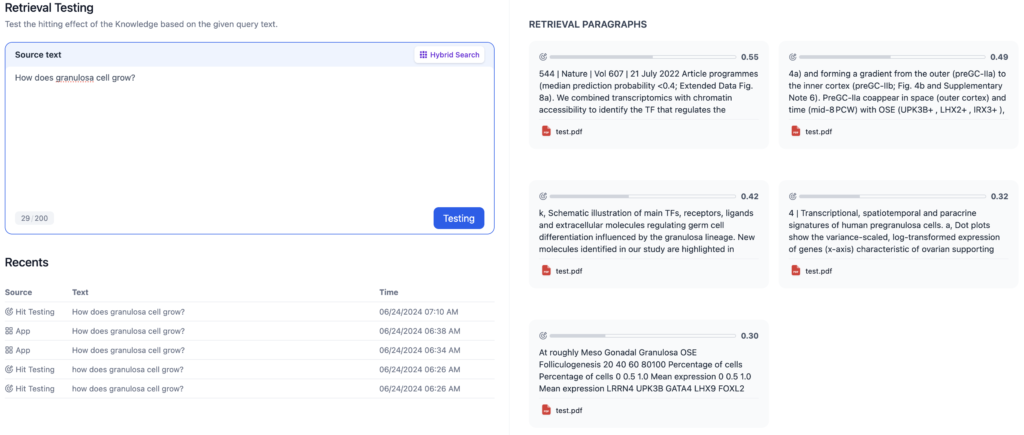
こちらも同じ様に見えます
これらのボックスをクリックすると
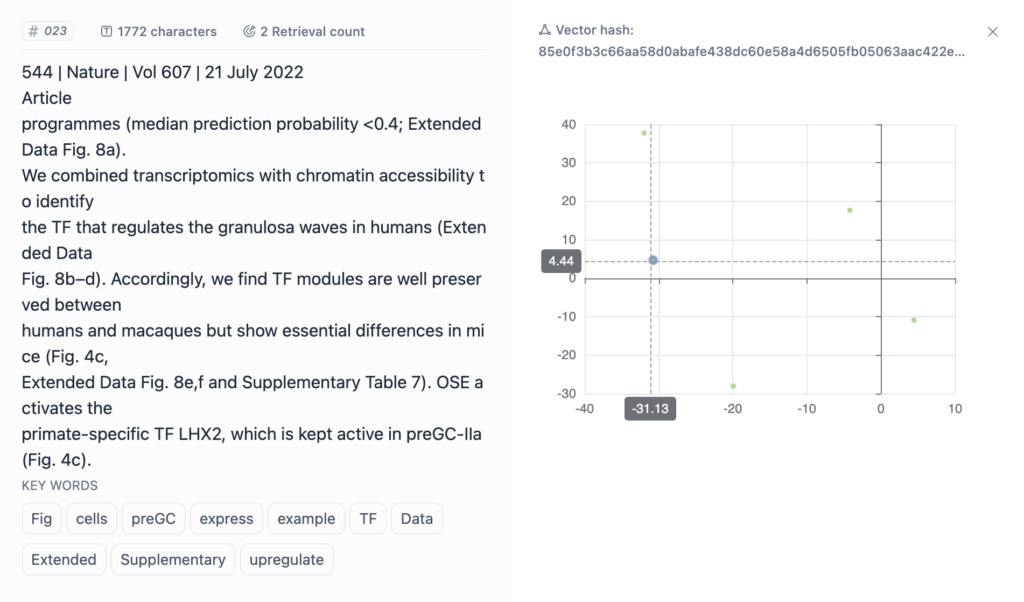
このようなものが現れて、これが、上記のベクトル空間なのだろうと推測はできるが、やっぱり詳細にはわかりません笑
ここでもPerplexityの解説を引用します
- テキストデータを数値ベクトルに変換するプロセスです。
- LLMやその他の機械学習モデルを使用して、テキストの意味を捉えた高次元ベクトルを生成します。
- 生成されたベクトルを効率的に検索できるように構造化して保存するプロセスです。
- ベクトルデータベースやベクトルインデックスを使用して、高速な類似性検索を可能にします。
ということで、ベクトル化されたチャンクを検索しやすいようにindex化しておくことになります。
その手法としてDifyでは
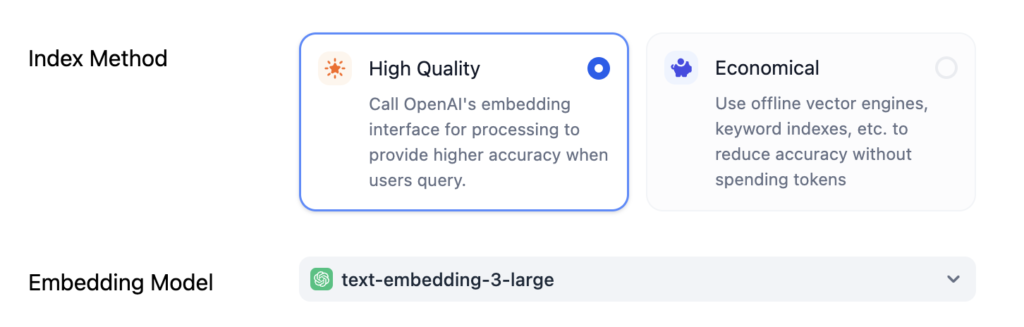
と選択できますが、上記の通りでいいと思います。
Custom機能を使って、いろいろなKnowledgeの構築方法の違いによる検索結果の際について説明しました。
今後
1,Retrieval settingについて
2,では実際にLLMに投げてみた結果どれがいいのか、どのようにKnowledgeを構築するのがいいのか
について検証結果をお伝えします。
Difyの操作記事一覧に戻る方はこちら
 【Dify】Dify操作記事まとめ(随時更新)
【Dify】Dify操作記事まとめ(随時更新)